Anwendungsbeispiel
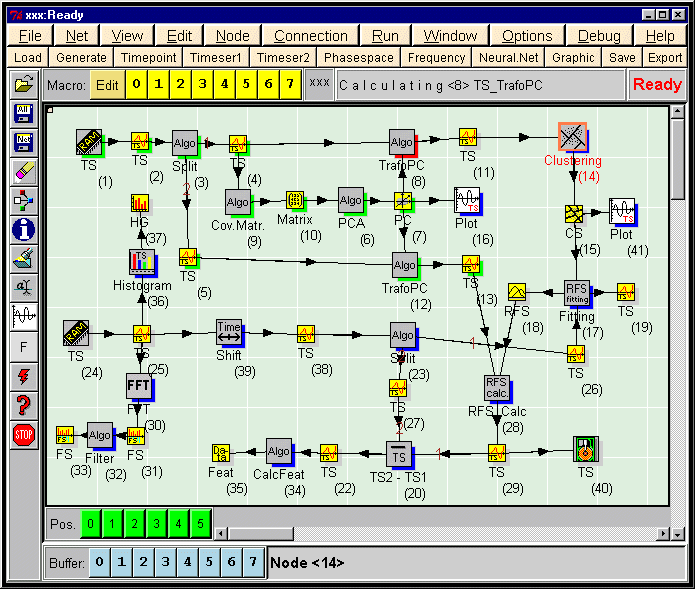 Abbildung 1: Bildschirmhardcopy des Data Stream Networks
mit einem kleinen Beispielnetz:
Abbildung 1: Bildschirmhardcopy des Data Stream Networks
mit einem kleinen Beispielnetz:
Stellen wir uns vor uns liegen Messungen eines Observablenvektors
A vor, der den Zustand eines dynamischen Systems S zu bestimmten Zeitpunkte
beschreibt. Diese Daten stehen uns in Form einer Zeitreihe als Datei auf
der Festplatte zur Verfügung. Sie werden durch den Zeitreihenlade-Knoten
(1) in das Netz gebracht und liegen dort durch Knoten (2) symbolisiert
zur Weiterverarbeitung bereit. Weiterhin haben wird Daten einer andere
Observable B des System, die über einen unbekannten inneren Zusammenhang
mit dem Zustand des Systems verknüpft ist (24). Wir stellen uns jetzt
die Aufgabe aus den in den Datensätzen enthaltenen Korrelationen die
Abbildung vom ersten Observablenvektor auf die zweite Observable zu schätzen.
Da wir eine allgemeingültige Abbildung suchen und nicht nur die vorliegenden
Datensätze approximieren wollen (Stichwort: Overfitting), teilen wir
unsere Daten in Trainings- und Testdatensatz auf. Mit Knoten (3) für
A und Knoten (23) für B wird diese Aufgabe erledigt. B ist eine multivariante
Zeitreihe und nehmen wir an enthält 100 Observablen pro Zeitpunkt,
die stark untereinander korreliert sind. Um das Rauschen herauszufiltern
und um die Algorithmen nicht mit unnötigen Datenmengen zu belasten
werden die Daten vorverarbeitet. Dazu bestimmen wir die Kreuzkorrelationsmatrix
(10) mit (9) und wenden eine Hauptkomponentenanalyse (PCA) in (6) an. Das
Ergebnis liegt in (7) vor und wird mit (16) in eine Grafik gedruckt und
interpretiert. Wir erkennen, daß nur die ersten 5 Komponenten relevante
Information enthalten und stellen dieses in der PCA-Transformation (8)
ein. Derselbe Parameter wird in (12) für den Testdatensatz (5) verwendet.
Die Menge der reduzierten jetzt 5-dimensionalen Datenpunkte (11) wird in
(14) einer Phasenraumclusterung unterzogen und liefert in (15) die Vorstufe
eines Neuronalen Netzes (RBFS). Das Netz wird in (17) mit den Trainingsdaten
(26) gefittet und liefert in (18) das RBFS als Ergebnis. Dieses wird mit
(28) auf den Testdatensatz (13) angewendet. Die berechnete Zeitreihe (29)
sollte jetzt ähnlich der gemessenen Zeitreihe (27) sein. Um dieses
zu prüfen werden sie voneinander abgezogen (20). Die Differenzzeitreihe
(22) wird dann auf ihre Kenngrößen, wie z.B. die Steuung untersucht.